

파이썬에서 BeautifulSoup을 사용하여 웹 크롤링을 하는 방법은 다음과 같습니다. 이 예시에서는 requests 라이브러리를 사용하여 웹 페이지의 HTML을 가져오고, BeautifulSoup을 사용하여 데이터를 파싱합니다.
- 필요한 라이브러리 설치하기:
먼저,beautifulsoup4와requests라이브러리가 필요합니다. 이들은 파이썬으로 웹 크롤링을 할 때 흔히 사용되는 라이브러리입니다. 아래의 명령어로 설치할 수 있습니다.
pip install beautifulsoup4 requests- 라이브러리 임포트하기:
파이썬 스크립트에서 필요한 모듈을 임포트합니다.
import requests
from bs4 import BeautifulSoup- 웹 페이지 가져오기:
requests를 사용하여 웹 페이지의 HTML을 가져옵니다.
url = 'http://example.com' # 크롤링할 웹사이트 주소
response = requests.get(url)- BeautifulSoup 객체 생성하기:
가져온 HTML을BeautifulSoup객체로 변환하여 파싱할 수 있게 합니다.
soup = BeautifulSoup(response.text, 'html.parser')- 필요한 데이터 찾기:
soup.find()또는soup.find_all()메서드를 사용하여 필요한 데이터가 있는 HTML 태그를 찾습니다.
# 예시: 모든 <a> 태그 찾기
links = soup.find_all('a')
for link in links:
print(link.get('href')) # 링크 URL 출력- 데이터 추출 및 사용:
필요한 데이터를 추출하여 사용합니다.
이 방법으로 다양한 웹사이트의 데이터를 크롤링할 수 있습니다. 하지만 웹사이트의 크롤링 정책을 확인하고, 해당 사이트의 서비스 약관을 준수하는지 확인하는 것이 중요합니다. 또한, 웹사이트에 과도한 요청을 보내 서버에 부담을 주지 않도록 주의해야 합니다.
네이버에서 홍삼을 검색하고, 광고는 제외하고 글 제목 불러오는 코드를 예제로 작성하겠습니다.
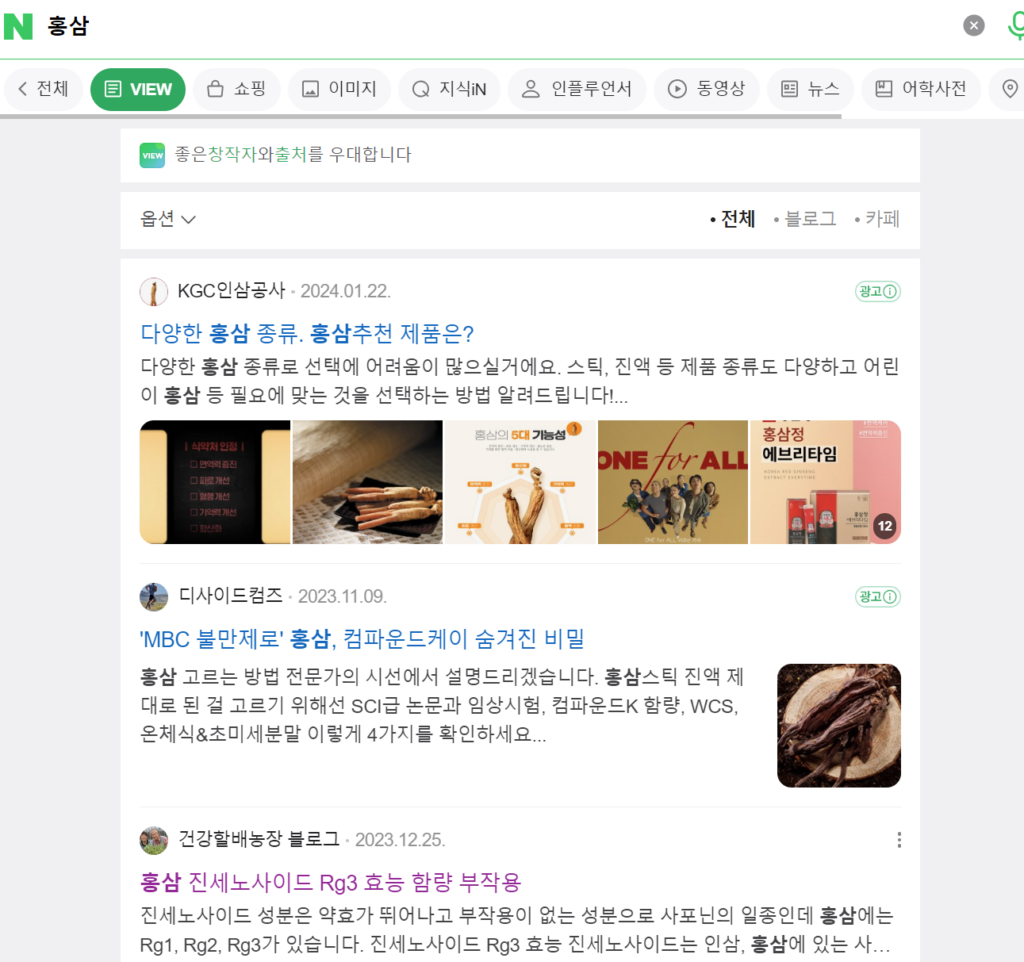
–
import requests
from bs4 import BeautifulSoup
header_user = {
"User-Agent": "Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Mobile Safari/537.36"
}
# 접속하고자 하는 url 입력.
base_url = "https://search.naver.com/search.naver?where=view&sm=tab_jum&query="
# search_url = input("검색어를 입력해주세요 : ")
search_url = "홍삼"
url = base_url + search_url
req = requests.get(url, headers=header_user)
html = req.text
soup = BeautifulSoup(html, "html.parser")
query = soup.select(".view_wrap")
for x in query:
ad = x.select_one(".spview.ico_ad")
if ad:
continue
else:
title = x.select_one(".title_link._cross_trigger")
name = x.select_one(".user_info > a")
tag = title["href"]
print(f"🔽\n글 제목 : {title.text}\n글 작성자 : {name.text}\n글 링크 : {tag}\n\n")
이 코드는 네이버에서 ‘홍삼’을 검색하고 그 결과를 가져오는 웹 크롤링 스크립트입니다. 각 줄에 대한 분석과 설명은 다음과 같습니다.
import requests
from bs4 import BeautifulSouprequests와BeautifulSoup라이브러리를 임포트합니다.requests는 웹 페이지에 요청을 보내기 위해,BeautifulSoup는 응답받은 HTML을 파싱하기 위해 사용됩니다.
header_user = {
"User-Agent": "..."
}- 사용자 에이전트(User-Agent)를 정의합니다. 이는 크롤링하는 프로그램을 웹 브라우저처럼 보이게 하는 데 사용됩니다. 여기서는 모바일 브라우저로 설정되어 있습니다.
base_url = "https://search.naver.com/search.naver?where=view&sm=tab_jum&query="- 네이버 검색 URL의 기본 형태를 정의합니다. 이 URL에 검색어를 추가하여 전체 검색 URL을 생성할 수 있습니다.
search_url = "홍삼"- 검색하고자 하는 키워드를 ‘홍삼’으로 설정합니다. 이 부분을 다른 키워드로 변경하면 다른 검색 결과를 얻을 수 있습니다.
url = base_url + search_url- 기본 URL과 검색어를 결합하여 검색을 위한 최종 URL을 생성합니다.
req = requests.get(url, headers=header_user)- 최종 URL로
requests.get메소드를 사용하여 HTTP GET 요청을 보냅니다. 이때 앞서 정의한 사용자 에이전트를 헤더에 포함시킵니다.
html = req.text
soup = BeautifulSoup(html, "html.parser")- 응답받은 HTML을 문자열로 저장하고,
BeautifulSoup을 사용하여 HTML을 파싱합니다.
query = soup.select(".view_wrap")- 검색 결과 페이지에서 클래스 이름이 ‘view_wrap’인 모든 요소를 찾습니다. 이 클래스는 네이버 검색 결과의 각 항목을 나타냅니다.
for x in query:
ad = x.select_one(".spview.ico_ad")
if ad:
continue
else:
title = x.select_one(".title_link._cross_trigger")
name = x.select_one(".user_info > a")
tag = title["href"]
print(f"🔽\n글 제목 : {title.text}\n글 작성자 : {name.text}\n글 링크 : {tag}\n\n")- 각 검색 결과 항목에 대해 루프를 돌면서 다음을 수행합니다:
ad = x.select_one(".spview.ico_ad"): 광고인지 확인합니다.if ad: continue: 항목이 광고라면 다음 항목으로 넘어갑니다.title = x.select_one(".title_link._cross_trigger"): 검색 결과의 제목을 찾습니다.name = x.select_one(".user_info > a"): 작성자의 이름을 찾습니다.tag = title["href"]: 검색 결과의 링크(URL)을 가져옵니다.- 마지막으로 제목, 작성자, 링크를 출력합니다.

답글 남기기